데이터베이스의 개요
데이터 저장소
- 데이터들을 논리적인 구조로 조직화하거나 물리적인 공간에 저장하는 것
데이터베이스
- 공동으로 사용될 데이터를 중복을 배제하여 통합하고 저장장치에 저장하여 운영하는 데이터
DBMS(DataBase Management System, 데이터베이스 관리 시스템)
- 사용자 요구에 따라 정보를 생성해주고 데이터베이스를 관리해주는 시스템
- DBMS의 필수 기능 : 정의, 조작, 제어
데이터의 독립성
- 논리적 독립성 : 응용 프로그램과 데이터베이스는 독립적이어서 데이터의 논리적 구조를 변경해도 응용 프로그램은 영향을 받지 않음
- 물리적 독립성 : 응용 프로그램과 물리적 장치는 독립적이어서 물리 장치를 변경하더라도 응용 프로그램은 영향을 받지 않음
스키마
- 데이터 베이스의 구조와 제약 조건에 관한 전반적인 명세를 기술한 것
- 외부 스키마 : 사용자나 응용 프로그래머가 개인적으로 필요한 데이터베이스의 논리적 구조를 정의
- 개념 스키마 : 데이터베이스의 전체적인 논리적인 구조로써 모든 사용자나 프로그램이 필요로 하는 데이터를 종합한 조직 전체의 데이터베이스
- 내부 스키마 : 물리적 저장장치에서 본 데이터베이스 구조로써 저장될 레코드의 형식, 표현 방법, 물리적 순서 등을 나타냄
데이터베이스 설계
데이터베이스 설계의 개념
- 사용자의 요구를 분석하여 그것에 맞게 설계하고 특정 DBMS로 데이터베이스를 구현하여 사용자들이 사용하는 것
데이터베이스 설계 순서
- 요구 조건 분석 → 개념적 설계 → 논리적 설계 → 물리적 설계 → 구현
- 요구 조건 분석 : 데이터베이스를 사용할 사람으로부터 필요한 용도를 파악
- 개념적 설계 : 개념 스키마, E-R 모델, 트랜잭션 모델링
- 논리적 설계 : 논리 스키마 설계 / 트랜잭션 인터페이스 설계 / 관계형 DB - Table, 계층형 DB - Tree, 망형 DB - Graph
- 물리적 설계 : 컴퓨터에 저장
- 데이터베이스 구현 : 위 단계로부터 설계된 스키마를 파일로 생성하는 과정
데이터베이스 설계 시 고려사항
- 무결성(=정확성), 일관성, 회복, 보안, 효율성, 데이터베이스 확장
데이터 모델의 개념
데이터 모델의 정의
- 현실 세계의 정보들을 컴퓨터에 표현하기 위해서 단순화, 추상화하여 체계적으로 표현한 개념적 모형
데이터 모델의 구성 요소
- 개체(Entity), 속성(Attribute), 관계(Relation)
데이터 모델의 종류
- 개념적 데이터 모델, 논리적 데이터 모델, 물리적 데이터 모델
데이터 모델에 표시할 요소
- 구조(Structure) : 개체 타입들 간의 관계, 데이터 구조 및 정적 성질 표현
- 연산(Operation) : 저장된 데이터를 처리하는 작업에 대한 명세, DB를 조작하는 기본 도구
- 제약 조건(Constraint) : 데이터의 논리적인 제약 조건
데이터 모델의 구성 요소 - 개체, 속성, 관계

개체의 정의
- 데이터베이스의 표현하려는 정보
개체의 특징
- 유형, 무형의 정보로서 서로 연관된 몇 개의 속성으로 이루어짐
- 유일한 식별자에 의해 식별이 가능
- 개체(튜플)의 수를 카디널리티라고 함
- 개체 인스턴스 : 개체를 구성하고 있는 속성들이 값을 가져 하나의 개체를 나타내는 것. 개체 어커런스라고도 함
- 자료 흐름도(DFD)를 통해 업무 분석을 했을 경우는 자료 저장소(Data Store)를 이용함.
속성의 정의
- DB를 구성하는 가장 작은 논리적인 단위
- 파일에서의 데이터 항목 또는 데이터 필드에 해당
속성의 특징
- 개체의 특성을 기술함
- 속성의 수를 차수 혹은 디그리(Degree)라고 함
속성의 종류
- 기본 속성 : 업무 분석을 통해 정의한 속성. 가장 많고 일반적 ex) 제품명
- 설계 속성 : 업무상 존재하지 않지만 설계 과정에서 도출해내는 속성 ex) 제품 코드
- 파생 속성 : 다른 속성으로부터 계산되거나 파생된 속성 ex) 제품 판매량, 판매 수익
속성의 분류
- 기본키 속성(Primary Key Attribute) : 개체를 식별할 수 있는 속성 ex) 학번
- 외래키 속성(Foreign Key Attribute) : 다른 개체와의 관계에서 포함된 속성
- 일반 속성 : 개체에 포함되어 있지만 기본키, 외래키가 아닌 속성

관계의 정의
- 개체 간의 논리적인 연결
관계의 형태
- 1:1, 1:N, N:M 3가지 관계가 있음
E-R(개체-관계) 모델
E-R 모델의 개요
- E-R 모델은 개념적 데이터 모델의 가장 대표적인 것
- 피터첸에 의해 제안되어 기본적인 구성 요소가 적립
- 데이터를 개체, 관계, 속성으로 묘사
E-R 다이어그램
- E-R 모델의 기본 아이디어를 쉽게 기호를 사용하여 시각적으로 표현한 것
- 표기법에는 피터 첸 표기법, 정보 공학 표기법 등이 있다.
피터 첸 표기법
- 사각형 : 개체 타입
- 마름모 : 관계 타입
- 타원 : 속성 타입
- 이중 타원 : 복합 속성
- 밑줄 타원 : 기본키 속성
- 복수 타원 : 복합 속성
- 관계 : 1:1, 1:N, N:M 같은 관계에 대한 대응 수

관계형 데이터베이스의 구조
관계형 데이터베이스
- 개체, 속성, 관계를 모두 표로 표현
- 간결하고 보기 편하며 다른 데이터베이스로의 변환이 용이
관계형 데이터베이스의 구조
- 튜플
-> 릴레이션을 구성하는 각각의 행
-> 튜플의 수를 카디널리티(Cardinality)라고 함
- 속성
-> 데이터베이스를 구성하는 가장 작은 논리적인 단위
-> 개체의 특성을 기술
-> 속성의 수를 디그리(Degree) 또는 차수라고 함
- 도메인
-> 속성이 취할 수 있는 값의 범위
-> ex) 학년의 도메인 : 1~4

릴레이션의 특징
- 튜플
-> 똑같은 튜플이 있을 수 없음. 모두 상이하다
-> 튜플에는 순서가 없음
-> 튜플의 삽입, 삭제로 인해 시간에 따라 변함
- 속성
-> 속성의 명칭은 유일해야 하지만 속성을 구성하는 값은 다를 수 있음
-> 속성에는 순서가 없음
-> 속성들은 원자 값(Atomic-Value)를 가짐
관계형 데이터 모델
- 2차원적인 표를 이용해서 데이터 상호 관계를 정의하는 DB 구조
관계형 데이터베이스의 제약 조건 - Key
Key의 개념
- key는 데이터베이스에서 조건에 맞는 튜플을 찾거나 정렬할 때 튜플을 서로 구분할 수 있는 기준이 되는 속성
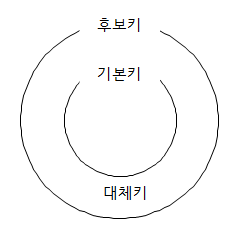
Key의 종류
- 후보키
-> 기본키로 사용할 수 있는 속성
-> 유일성과 최소성의 성질을 만족
- 기본키
->후보 키 중에서 선정된 Main Key로 중복된 값을 가질 수 없음
->후보 키의 부분집합
-> NULL 값을 가질 수 없음(=개체 무결성)
-> NULL 값 : 정보의 부재를 나타내기 위해 사용하는 값. 0의 값이 아님
- 대체키
->후보 키가 둘 이상일 때 기본키를 제외한 나머지 후보키
- 슈퍼키
-> 한 가지 속성일 땐 Key가 될 수 없지만 여러 속성이 뭉쳐서 Key의 속성을 가짐
-> 유일성의 성질을 만족
- 외래키
-> 다른 릴레이션의 기본 키를 참조한 것
->외래 키의 값은 참조한 릴레이션의 기본키 값과 동일해야 함(=참조 무결성)
관계형 데이터베이스의 제약조건 - 무결성
무결성의 개념
- 무결성은 데이터베이스의 저장된 데이터 값과 그것이 표현하는 실제 값이 일치하는 정확성을 의미
무결성의 종류
- 개체 무결성 : 기본키를 구성하는 어떤 속성도 NULL 값이나 중복 값이면 안됨
- 도메인 무결성 : 속성의 값이 도메인에 속한 값이어야 함
- 참조 무결성 : 외래 키의 값은 참조한 릴레이션의 기본키 값과 동일해야 함
- 사용자 정의 무결성 : 속성 값들은 사용자가 정의한 제약 조건에 만족해야 함
무결성 강화
- 애플리케이션
-> 무결성 조건을 검증하는 코드를 데이터를 조작하는 프로그램 내에 추가
-> 사용자 정의 같은 복잡한 무결성 조건의 구현이 가능
- 데이터베이스 트리거
-> 트리거 : 데이터베이스 시스템에 이벤트가 발생할 때마다 자동으로 수행되는 절차형 SQL
- 제약 조건
-> 데이터베이스 제약 조건을 설정하여 무결성을 유지
관계 대수 및 관계 해석
관계 데이터 언어
- 관계 대수 : 관계형 데이터베이스에서 원하는 정보와 그 정보를 검색하기 위해 유도하는 것을 기술하는 절차적 언어
- 관계 해석 : 관계 데이터의 연산을 표현하는 비절차적 언어
관계 대수의 연산자
- Select
-> 조건을 만족하는 튜플을 구하여 새로운 릴레이션을 만드는 연산
-> 수평 연산이라고 함
-> 연산자의 기호는 시그마(σ)를 사용
-> 표기 형식 : σ<조건>(R) (여기서 R은 릴레이션을 의미)
-> ex) σ평균>80 (성적) : 성적 릴레이션에서 평균값이 80 이상인 튜플을 구함

- Project
-> 속성만 추출하여 새로운 릴레이션을 만드는 연산
-> 수직 연산이라고 함
-> 연산 결과에 중복이 발생하면 제거
-> 연산자의 기호는 파이(π)를 사용
-> 표기 형식 : π<조건>(R)
-> ex) π이름, 평균(성적) : 성적 릴레이션에서 이름, 평균 속성을 추출

- Join
-> 두 릴레이션을 합쳐서 새로운 릴레이션을 만드는 연산
-> Join의 결과로 만들어진 릴레이션의 차수는 두 차수의 합
-> Join의 결과는 교차곱(Cartesian Product)을 수행 후 Select 한 것과 같음
-> 연산자의 기호는 ⋈를 사용
-> 표기 형식 : R⋈키 속성 r=키 속성 sS
-> ex) 성적⋈이름=이름 명부 : 성적 릴레이션과 명부 릴레이션을 이름 속성을 기준으로 합침

-> 자연 조인 : Join의 조건이 같을 때 동일한 속성이 두 번 나타나 중복된 속성을 제거하여 한번만 표기하는 방법
-> 자연 조인이 성립되려면 두 릴레이션의 속성명과 도메인이 같아야 함
- Division
-> R ⊃ S인 두 릴레이션이 있을 때, R의 속성이 S의 속성의 값을 모두 가진 튜플에서 S가 가진 속성을 제외한 속성만을 구하는 연산
-> 연산자의 기호는 ÷를 사용
-> 표기 형식 : R [속성 r ÷ 속성 s] S
-> ex) 성적 [평균 ÷ 기준] 기준

- 일반 집합 연산자
-> 합집합(∪) : 두 릴레이션의 튜플의 합집합. 중복되는 튜플은 제거
-> 교집합(∩) : 두 필레이션의 튜플의 교집합.
-> 차집합(-) : 두 릴레이션의 튜플의 차집합.
-> 교차곱(×) : 두 릴레이션의 튜플들의 순서쌍. 차수(Degree)는 서로 더한 값 카디널리티(Cardinality)는 서로 곱한 값

실기 정리
2021 정보처리기사 실기 정리
본 정리 글은 시나공 정보처리기사 실기책과 2020년 기출문제 등을 참고하여 작성하였습니다. -> 책 정보 확인하기 시나공 정보처리기사 실기 수험생들의 궁금증을 100% 반영시험에 나올만한 내
1d1cblog.tistory.com
'2020(개정) 이후 정보처리기사 > 2장 : 데이터 입출력 구현' 카테고리의 다른 글
| 2021 정보처리기사 실기 - 2. 데이터 입출력 구현(4) (0) | 2021.10.04 |
|---|---|
| 2021 정보처리기사 실기 - 2. 데이터 입출력 구현(3) (0) | 2021.10.04 |
| 2021 정보처리기사 실기 - 2. 데이터 입출력 구현(2) (0) | 2021.09.26 |