우리가 보통 배열을 사용한다면 아래와 같은 코드로 사용합니다.
int arr[10];
int* pArr = new int[10];위와 같이 사용할 경우 정적 배열의 경우 고정된 크기로 설정이 가능하고 인덱스를 넘어 참조하려 할 경우 Segmanatation fault가 발생합니다. 동적 배열의 경우 new에 대한 delete가 빠질 경우 그에 따른 메모리 누수(memory leak)가 발생할 수 있습니다.
이럴 때 C++ 스타일의 배열인 std::array를 사용하면 좋습니다. std::array를 사용할 경우 메모리도 자동으로 할당, 해제하여 사용하기에도 안전합니다.
array의 경우 아래처럼 template을 통해 타입을 지정할 수 있고 두 번째 인자로 크기를 상수로 넘겨주게 됩니다.

std::array를 사용하려면 #include<array>를 추가해주어야 합니다. 기본적으로 접근은 특정 인덱스에 접근하는 방법과 정해진 위치(앞, 뒤)에 접근하는 방법이 있는데 특정 인덱스에 접근하기 위해서는 기존처럼 [] 연산자를 사용하거나 at 함수를 사용할 수 있습니다. 혹은 정해진 위치를 접근하기 위해 front() 함수나 back() 함수를 통해 접근도 가능합니다.
#include <iostream>
#include <array>
using namespace std;
int main(int argc, char* argv[])
{
std::array<int, 10> arr;
arr[0] = 1;
cout << "arr[0] = " << arr[0] << endl;
cout << "arr.at(0) = " << arr.at(0) << endl;
cout << "arr.front() = " << arr.front() << endl;
}만약에 인덱스 범위를 넘어서 참조하려 한다면 기존 배열의 경우에는 segmentation fault가 났겠지만 std::array는 좀 다릅니다. [] 연산자를 통해 접근할 경우 쓰레기 값이 출력되고 at을 통해 접근 시 std::out_of_range 에러가 납니다.
이렇게 되면 예외 처리를 통해 에러를 방지할 수 있습니다.
#include <iostream>
#include <array>
using namespace std;
int main(int argc, char* argv[])
{
std::array<int, 3> arr{1,2,3}; // 초기화
try {
for ( int i =0; i <= 3; i++) {
cout << "arr.at(" << i << ") = " << arr.at(i) << endl;
}
} catch ( const std::out_of_range& e) {
cout << "out of range" << endl;
}
}이 std::array를 매개변수로 던지는 방법은 const 참조형으로 넘기는 방법과 data 함수를 통해서 저장되어 있는 배열을 넘기는 방법이 있습니다.
#include <iostream>
#include <array>
using namespace std;
void print2constarg(const std::array<int,3>& arr) {
for ( int i : arr ) {
cout << i;
}
cout << endl;
}
void print2data(const int* pArr, std::size_t size) {
for (std::size_t i = 0; i < size; i++) {
cout << pArr[i] << ' ';
}
cout << endl;
}
int main(int argc, char* argv[])
{
std::array<int, 3> arr{1,2,3};
print2constarg(arr);
print2data(arr.data(), arr.size());
}위에서 print2constarg의 매개변수 std::array의 크기를 고정시켰는데 만약에 크기가 다른 array를 받으면 에러가 발생합니다.
이것을 방지하기 위해서 변수 크기를 템플릿화 해서 사용한다면 다른 크기의 array도 사용이 가능해집니다. 이렇게 타입도 템플릿 매개변수로 지정할 수 있지만 타입이 기본 자료형이 아닌 경우에 기본 출력이 아닌 방법을 사용해야 할 수 있기 때문에 타입은 지정하는 게 안전하다고 생각합니다.
template <size_t T>
void print2constarg(const std::array<int,T>& arr) {
for ( int i : arr ) {
cout << i;
}
cout << endl;
}
void print2data(const int* pArr, std::size_t size) {
for (std::size_t i = 0; i < size; i++) {
cout << pArr[i] << ' ';
}
cout << endl;
}
int main(int argc, char* argv[])
{
std::array<int, 11> arr{1,2,3};
print2constarg(arr);
print2data(arr.data(), arr.size());
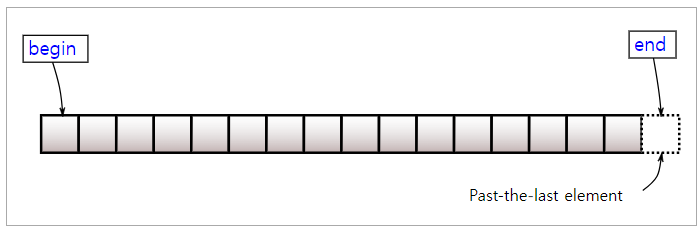
}마지막으로 반복자를 통해 요소를 접근하는 방법입니다. begin은 첫 번째 원소를 가리키는 반복자를 반환, end는 마지막 원소의 다음을 가리키는 반복자를 반환합니다.
#include <iostream>
#include <array>
using namespace std;
template <size_t T>
void print2constarg(const std::array<int,T>& arr) {
for ( auto i : arr ) {
cout << i;
}
cout << endl;
for ( auto it = arr.begin(); it!= arr.end(); ++it ) {
cout << *it;
}
cout << endl;
}
int main(int argc, char* argv[])
{
std::array<int, 3> arr{1,2,3};
print2constarg(arr);
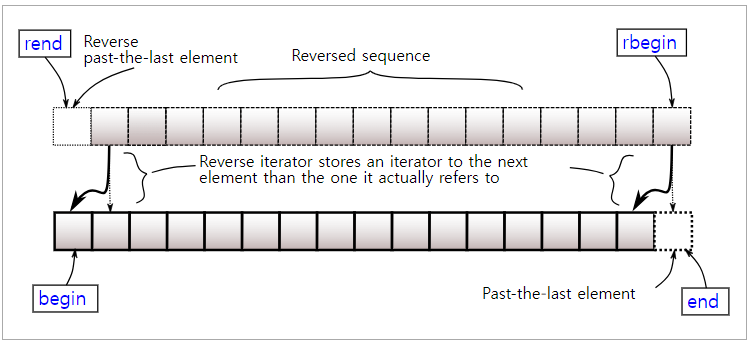
}여기에 const_iterator를 사용할 수 있는 cbegin, cend 그리고 reverse_iterator를 사용하는 rbegin, rend가 있지만 반복자에 const가 붙는 것, begin/end가 반대인 것이 생각하면 됩니다.
std::array - cppreference.com
template< class T, std::size_t N > struct array; (since C++11) std::array is a container that encapsulates fixed size arrays. This container is an aggregate type with the same semantics as a struct holding a C-style array T[N] as its only non-s
en.cppreference.com
C 스타일의 배열보다는 std::array가 더 낫지만 array도 몇가지 단점이 있는데 크기를 상수로 전달해야 하고 요소를 추가/삭제할 수 없다는 제약이 있습니다. 이러한 제약을 해결한 std::vector가 있습니다.
vector는 생성 시에 굳이 크기를 넘겨주지 않아도 됩니다. 혹은 넘겨주고 그 요소들을 특정 값으로 모두 초기화할 수도 있습니다.
#include <iostream>
#include <vector>
using namespace std;
int main(int argc, char* argv[])
{
std::vector<int> vecInt;
std::vector<int> vecInt2 = {1,2,3};
std::vector<int> vecInt3(10);
std::vector<int> vecInt4(10,0);
}vector는 크기가 가변이기 때문에 추가/삭제도 가능한데 추가를 위해 insert(), push_back()를 사용합니다. insert의 경우 추가를 원하는 위치를 같이 넘겨 원하는 위치에 값을 추가하고 push_back의 경우에는 맨 뒤에 요소를 추가합니다.
#include <iostream>
#include <vector>
using namespace std;
int main(int argc, char* argv[])
{
std::vector<int> vecInt;
vecInt.push_back(0);
vecInt.push_back(30);
for ( int i : vecInt ) {
cout << i << ' ';
} cout << endl;
vecInt.insert(vecInt.begin()+1,10);
for ( int i : vecInt ) {
cout << i << ' ';
} cout << endl;
}
추가 시에 벡터가 가질 수 있는 capacity를 체크 후 모자르다면 capacity를 늘리고 추가합니다. capacity는 vector가 수용할 수 있는 요소 개수 정도라고 생각하면 되고 크기(size)는 현재 vector가 가지고 있는 요소 개수라고 생각하면 됩니다.
push_back의 경우에는 단순히 뒤에 추가하는 작업이기 때문에 O(1)의 시간 복잡도를 나타내지만, insert의 경우 특정 위치에 요소를 추가하면 요소들을 복사/이동 해야하기 때문에 O(n)의 시간 복잡도를 나타냅니다. 그렇기 때문에 추가/삭제가 빈번히 일어나는 경우 vector 자료구조를 사용하는게 오히려 독이될 수 있습니다.
추가에 있어 emplace 함수가 있는데 이 함수는 객체를 요소로 추가할 때 임시 객체를 생성할 필요 없이 사용 가능하게 해주는 함수입니다. 이렇게 봤을 땐 무조건 emplace가 좋을거 같지만 형 변환 등에 취약할 수 있습니다. 관련해서 정리가 잘 되어 있는 블로그 포스팅 링크 남겨둡니다.
emplace_back 과 push_back 의 차이
item 타입의 생성자가 타입을 인자로 받는다면? push_back 함수는 '객체' 를 집어 넣는 형식으로, 객체가 없이 삽입을 하려면 "임시객체 (rvalue) " 가 있어야 합니다. 또는 암시적 형변환이 가능하다면,
openmynotepad.tistory.com
std::vector - cppreference.com
template< class T, class Allocator = std::allocator > class vector; (1) (2) (since C++17) 1) std::vector is a sequence container that encapsulates dynamic size arrays. The elements are stored contiguously, which means that elements can be acces
en.cppreference.com
'Programming > C++' 카테고리의 다른 글
| [C++] Template(1) (2) | 2023.09.19 |
|---|---|
| [C++] std::forward_list, std::list (0) | 2023.07.18 |
| [C++] 람다 함수 (0) | 2023.04.07 |
| [Effective C++] 4. 설계 및 선언 (0) | 2022.11.14 |
| [Effective C++] 3. 자원 관리 (0) | 2022.11.07 |
